grep and egrep search files
for patterns and print all lines that contain
a match to at least one of the patterns
(in expression and exprfile).
By default grep
uses basic regular expressions
(see below for
details on regular expressions).
If the -E or -F options are specified,
grep behaves respectively
like egrep or fgrep.
See ``Options''.
Be careful using the characters ``$'', ``*'', ``['', ``^'',
``|'',``('', ``)'', and ``\''
in the expression because they are also meaningful to the shell.
It is safest to enclose the entire expression in single quotes
`...` or put the expression in an exprfile.
A null pattern matches all lines.
If no files are specified, grep and egrep assume standard input.
If a ``-'' is specified as a file, standard input is used.
Normally, each line matched is copied to standard output.
The filename is printed before each line matched if there is more than
one input file, unless the -h option is specified.
Options
-E
Behave like
egrep.
All specified patterns (in expression and
exprfile) are then full regular expressions.
When this option is
specified, all other grep options (except -F)
have the same effect as usual, and the same effect as they
have for
egrep.
-F
Behave like
fgrep.
All specified patterns (in expression and
exprfile) are then fixed strings.
When this option is
specified, all other grep options (except -E) have the
same effect as usual, and the same effect as they have for
fgrep(1).
-Nmax
Output no more than max lines which match an expression.
The value of max must be an integer greater than zero.
For example, grep -N 1 '^main' .c would print the first
instance of a line beginning with ``main'' in all files that match
the expansion of ``.c''.
-b
Precede each line by the block number on which it was found.
This can be useful in locating block numbers by context (first block is 0).
-c
Print only a count of the lines that match the patterns.
-eexpression
Specify one or more patterns (regular expressions or strings) to be
used during the search for input.
The patterns in expression are
separated by newline characters.
Two adjacent newlines
indicate a null pattern.
The last pattern does not require a
terminating newline.
When multiple -e or -f options are
specified, all the patterns specified will be used.
(Obviously, if
expression is to contain newlines, it should be quoted.)
This option is useful for specifying patterns that begin with a ``-''.
-fexprfile
Read one or more patterns (regular expressions or strings) from
exprfile.
The patterns in exprfile are terminated by a
newline character.
An empty line in exprfile indicates a
null pattern.
When multiple -e or -f options are
specified, all the patterns specified will be used.
-h
Suppress printing of filenames when searching multiple files.
-i
Ignore uppercase/lowercase distinction during comparisons, as defined
by the character classification locale
(see LANG On
environ(5)).
-l
Print the names of files with matching lines, one per line.
Does not repeat a file name even if multiple matches are present.
If the input file is stdin,
then a name such as (standard input) will be written,
depending upon the message locale.
-n
Precede each line by its line number in the file (first line is 1).
-q
Quiet, do not write anything to the standard output, regardless of any
matches.
Exits with zero if any input line is matched.
-s
Suppress error messages about nonexistent or unreadable files.
-v
Print all lines except those that contain a pattern.
-x
Match only lines for which the pattern matches the entire line.
For
character strings, the pattern must match all characters in the line.
For regular expressions, this option is equivalent to placing a
``^'' at the start of the pattern, and a ``$'' at the end
of the pattern.
Regular expressions
Regular expressions (REs) enable you to select specific strings from a
set of character strings.
REs are context-independent syntax representing a variety
of character sets and character set orderings.
These character sets are
interpreted according to the current locale.
While many REs can be interpreted differently
depending on the current locale, many features (such as character class
expressions) provide for contextual invariance across locales.
Basic Regular Expressions (BREs) are supported by default by grep.
A slightly different notation, called Extended Regular Expressions (EREs),
are supported by grep -E (or egrep). The following
applies to both BREs and EREs.
Matching is based on the bit pattern used for encoding the character,
not on the graphic representation of the character.
Searches for a matching sequence start at the beginning
of a string and stop when the first sequence matching the expression is found.
If the pattern allows a variable number of matching characters
(and there is more than one such sequence
starting at that point) then the longest sequence is matched.
Consistent with the whole match being the longest of the
leftmost matches, each subpattern, from left to right, matches
the longest possible string. For this purpose, a null string
is considered to be longer than no match at all.
For example, matching the BRE \(.*\).* against
``abcdef'', the subexpression (\1) is ``abcdef'', and matching
the BRE \(a*\)* against ``bc'', the subexpression
(\1) is the null string.
Basic regular expressions
For BREs, ordinary characters, a special character preceded by a backslash,
or a period, matches
a single character.
A bracket expression matches a single character or collating element.
An ordinary character is a BRE that matches itself
(that is, any character in the supported
character set, except for the BRE special characters listed below).
The interpretation of an ordinary character preceded by a backslash (\)
is undefined, except for
the characters ``)'', ``('', ``{'', and ``}'',
the numbers 1 through 9,
and a character inside a bracket expression.
In certain contexts,
a BRE special character has special properties.
The BRE characteristics and the contexts
in which they have their special meaning are:
The period (.), left bracket ([), and backslash (\)
are special except when used in a bracket expression.
If an expression contains a left bracket not
preceded by a backslash (and that is not part of a bracket expression),
it will yield undefined results.
The asterisk (*) is special except when used in a bracket expression,
as the first
character of an entire BRE (after an anchor circumflex, if any), or as the first
character of a subexpression (after an anchor circumflex, if any).
The circumflex (^) is special when used as an anchor or as the first character
in a bracket expression.
The dollar sign ($) is special when used as an anchor.
If a period (.) is used outside a bracket expression,
then it is a BRE matching any character in the supported character set, except NUL.
A bracket expression (that is, an expression enclosed in square brackets,[]),
is an RE that matches a single
collating element contained in the nonempty
set of collating elements the bracket
expression represents.
The following rules and definitions apply:
A bracket expression is a matching or nonmatching list expression.
It consists of one or more expressions. These include collating elements,
collating symbols, equivalence
classes, character classes, or range expressions.
The right bracket (]) loses its special meaning and represents
itself in a bracket expression if it occurs first
in the list (after an initial circumflex, if any).
Otherwise, it terminates the bracket expression unless it appears
as part of a collating symbol, equivalence class,
or character class construct (such as [.].] and [=a=]).
The special characters period (.), asterisk (*),
left bracket ([),
and backslash (\)
lose their
special meaning within a bracket expression.
The [., [=, and [: character sequences
are
special inside a bracket expression and are used to delimit collating symbols, equivalence class expressions, and
character class constructs. These character sequences are followed by a character sequence and the matching
terminating sequence .], =], or :].
A matching list expression specifies a list that matches
any one of the expressions represented in the list.
The first character in the list can not be the circumflex.
For example, [abc] is an RE
that matches any of ``a'', ``b'', or ``c''.
A nonmatching list expression begins with a circumflex
and specifies a list that matches any character or collating element except
for the expressions represented in the list after the leading circumflex.
For example, [^abc] is an RE that matches any character
or collating element except ``a'', ``b'', or ``c''.
The circumflex has this special meaning only when it occurs first in the list,
immediately following the left bracket.
A collating symbol is a collating element enclosed within bracket-period
([. .]) delimiters. Multiple-character collating elements are represented
as collating symbols when it is necessary to distinguish them from a
list of the individual characters that make up the multiple-character
collating element.
For example,
if the string ``ch'' is a two-character collating element in the current
collation sequence with the associated collating symbol <ch>,
the expression [[.ch.]] is treated as an RE matching
ch, while [ch] is treated as an RE matching the character
``c'' or ``h''.
Collating symbols are recognized only inside bracket expressions.
This implies that the RE [[.ch.]]*c
matches the first through fifth character in the string ``chchch''.
If the string
is not a collating element in the current collating sequence definition,
or if the
collating element has no characters associated with it, the symbol
is treated as an invalid expression.
An equivalence class expression represents the set of
collating elements belonging to an equivalence class,
as defined by the collation portion of the current locale.
Only primary equivalence classes are recognized. The class is expressed
by enclosing any one of the collating elements
in the equivalence class within a bracket-equal ([= =]) delimiters.
For example, if ``a, \o'a`','' and ``\o'a^'''
form an equivalence class,
then [[=a=]b], [[=\o'a`'=]b], and [[=\o'a^'=]b]
are each equivalent
to ``[a\o'a`'\o'a^'b]''.
If the collating element does not belong to an equivalence class,
the equivalence class
expression is treated as a collating symbol.
A character class represents the set of characters
belonging to a character class,
as defined in the character classification portion of the current locale.
All character classes specified in the current locale are recognized.
A character class expression can be expressed as a character
class name enclosed
within bracket-colon ([: :]) delimiters.
These are supported on all conforming
implementations:
[:alnum:]
[:cntrl:]
[:lower:]
[:space:]
[:alpha:]
[:digit:]
[:print:]
[:upper:]
[:blank:]
[:graph:]
[:punct:]
[:xdigit:]
Other, locale-dependent character classes may also be recognized.
A range expression represents the set of collating elements
that fall between two elements in the current collation sequence.
It is expressed as the starting point and the ending point
separated by a hyphen.
Range expressions are not used portably
because their behavior
depends on the collating sequence order defined by the current locale.
In the following, all examples assume the collation sequence specified
for the default locale, unless another collation sequence is specifically defined.
The starting range point and the ending range point is a collating element or
symbol. An equivalence class expression used as a starting
or ending point of a range expression produces unspecified results.
The ending range point collates equal to or higher
than the starting range point; otherwise, the expression is treated as invalid.
The order used is the order in which the collating elements are
specified in the current locales' collation definition. One-to-many mappings
are not performed. For example, assuming that the character eszet ()
is placed in the collation sequence after ``r'' and ``s''
but before ``t'' (and that it maps to the sequence ``ss''
for collation purposes),
then the expression [r-s] matches only ``r'' and ``s'',
but the expression
[s-t] matches ``s'', ``'', or ``t''.
The interpretation of range expressions where the ending
range point is also the starting
range point of a subsequent range expression is undefined.
The hyphen character is treated as itself if it occurs first
(after an initial circumflex, if any)
or last in the list, or as an ending range point in a range expression.
As examples, the expressions [-ac] and [ac-] are
equivalent and match any of the characters ``a'', ``c'', or ``-'';
the expressions
[\o'^'-ac] and [\o'^'ac-] are equivalent and match
any characters except ``a'', ``c'', or ``-''; [%--]
matches any of the characters
between ``%'' and ``-'' inclusive; the expression [--@]
matches any of the characters
between ``-'' and ``@'' inclusive, and the expression [a--@]
is invalid
because the letter ``a'' follows the symbol ``-'' in the default locale.
To use the hyphen as the starting range point, it either comes first in the
bracket expression or is
specified as a collating symbol. For example, [][.-.]-0],
which matches either a right bracket or any character or
collating element that collates
between hyphen and 0, inclusive.
The
following rules can be used to construct BREs matching multiple
characters from BREs matching a single character.
The concatenation of BREs matches the concatenation of the strings
matched by each component of the BRE.
A subexpression can be defined within a BRE by enclosing
it between the character
pairs ``\('' and ``\)''. Such a subexpression matches whatever
it would have matched without the ``\('' and ``\)'', except that anchoring
within subexpressions is optional behavior.
Subexpressions can be arbitrarily nested.
The backreference expressions \n matches the same (possibly empty)
string of characters as was matched by a subexpression enclosed between
``\('' and ``\)'' preceding the \n.
The character n is a single digit from 1 through 9,
specifying the n-th subexpression
(the one that begins with the nth
``\('' and ends with the corresponding paired ``\)''].
The expression is invalid if less than n subexpressions
precede the \n.
For example, the expression ^\(.*\)\1$ matches a
line entirely consisting of two adjacent appearances of the same string and the
expression \(a\)*\1 fails to match ``a''.
When a BRE matching a single character, a subexpression, or a backreference is
followed by the special character asterisk, it matches (together with that
asterisk) what zero or more consecutive occurrences of the BRE would match.
For example, [ab]* and [ab][ab] are equivalent
when matching the string ``ab''.
When a BRE matching a single character, a subexpression,
or a backreference is followed by an interval expression of the
format \{m\}, \{m,\}, or \{m,n\},
it matches (together with that interval expression)
what repeated consecutive occurrences of the BRE would match.
The values of m and n are decimal integers in the range
0mn{RE_DUP_MAX}
where m specifies
the exact or minimum number of
occurrences and n specifies the maximum number of occurrences.
The expression \{m\}
matches exactly m occurrences of the preceding BRE,
\{m,\} matches
at least m occurrences,
and \{m,n\} matches any number of occurrences
between m and n, inclusive.
For example, in the string ``abababccccccd'', the
BRE c\{3\}
is matched by characters
seven through nine, the BRE \(ab\)\{4,\} is not matched at all,
and the BRE c\{1,3\}d is matched by characters ten through thirteen.
An occurrence of multiple adjacent duplication symbols
(``*'' and intervals) produces
undefined results.
The BRE order of precedence, from high to low, is shown in the following table:
Collation-related bracket symbols
[= =] [: :] [. .]
Escaped characters
\special character
Bracket expression
[ ]
Subexpressions/backreference
\(\) \n
BRE duplication
*\{m,n\}
Concatenation
Anchoring
^ $
A BRE can be limited to matching strings that begin or end a line;
this is called
anchoring.
The circumflex and dollar sign special characters
are considered BRE anchors in the following contexts:
A circumflex is an anchor when used as the first character of an entire BRE.
The implementation may treat the circumflex as an anchor when used as the
first character of a subexpression.
The circumflex anchors the expression (or optionally, the subexpression) to the
beginning of a string; only sequences starting at the first
character of a string are matched by the BRE.
For example, the BRE ^ab matches ``ab'' in the
string ``abcdef'', but fails to match in the string ``cdefab''.
The BRE \(^ab\) may match the former string. A portable
BRE escapes a leading circumflex in a subexpression to
match a literal circumflex.
A dollar sign is an anchor when used
as the last character of an entire BRE.
The implementation may treat a dollar sign as an
anchor when used as the last character of a subexpression.
The dollar sign anchors the expression (or optionally, the subexpression)
to the end of the
string being matched; the dollar sign can be said to match the "end-of-string"
following the last character.
A BRE anchored by both ``^'' and ``$'' matches
only an entire string.
For example,
the BRE ^abcdef$ matches strings consisting only of ``abcdef''.
Extended regular expressions
An ERE ordinary character, a special character preceded by a backslash,
or a period matches a single character.
A bracket expression matches
a single character or a single collating element.
An ERE matching
a single character enclosed in parentheses matches the same way an
ERE without parentheses would have
matched.
An ordinary character is an ERE that matches itself.
An ordinary character
is any character in the supported character set,
except for the ERE special characters
listed below. The interpretation of an ordinary character preceded by a
backslash is undefined.
An ERE special character has special
properties in certain contexts.
Outside those
contexts, or when preceded by a backslash,
such a character is an ERE that matches the
special character itself.
The ERE special characters and the
contexts in which they have their special meanings are
defined as follows:
The period (.), left bracket ([), backslash (\) and
left parenthesis (()
are special except when used in a bracket expression.
Outside a bracket expression, a left parenthesis immediately
followed by a right parenthesis produces undefined results.
The right parenthesis ()) is special when matched with a preceding
left parenthesis, both outside a bracket expression.
The asterisk (*), plus sign (+), question mark (?),
and left brace ({)
are special except when used in a bracket expression. Any of the following uses
produce undefined results:
These characters appear first in an ERE or
immediately following a vertical line,
circumflex, or left parenthesis.
A left brace is not part of a valid interval expression.
The vertical line (|) is special except when used in a bracket expression.
A vertical line appearing first or last in an ERE, immediately following
a vertical line or left parenthesis, or immediately preceding a
right parenthesis
produces undefined results.
The circumflex (^) is special when used as an anchor or as the first
character of a bracket expression.
The dollar sign ($) is special when used as an anchor.
A period (.), when used outside a bracket expression,
is an ERE that matches any character in the supported character set except NUL.
The rules for ERE bracket expressions are the same as for
RE bracket expressions.
The following rules are used to construct EREs matching multiple characters
from EREs matching a single character:
A concatenation of EREs matches the concatenation of
the character sequences matched by each
component of the ERE.
A concatenation of ERE enclosed in parentheses matches whatever
the concatenation without the parentheses matches.
For example, both the ERE cd
and the ERE (cd) are matched by the third and fourth character
of the string ``abcdefabcdef''.
When an ERE matching a single character or an ERE enclosed in
parentheses is followed by the special character plus sign (+),
it matches
(together with the plus sign) what one or more consecutive
occurrences of the ERE would match.
For example, the ERE b+(bc) matches the fourth through seventh characters
in the string ``acabbbcde''.
Furthermore,
[ab]+ and [ab][ab]* are equivalent.
When an ERE matching a single character or an ERE enclosed in parentheses
is followed by the special character asterisk (*), it matches (together with
that asterisk) what zero or more
consecutive occurrences of the ERE would match.
For example,
the ERE b*c matches the first character in the string ``cabbbcde''
and the ERE ``b*cd'' matches the third through
seventh characters in the string
``cabbbcdebbbbbbcdbc''.
Furthermore, [ab]* and [ab][ab] are
equivalent when matching the string ``ab''.
When an ERE matching a single character or an ERE enclosed in parentheses
is followed by the special character question mark (?), it
matches (together with that question mark)
what zero or one consecutive occurrences of the ERE would match.
For example, the ERE b?c matches the second
character in the string acabbbcde.
When an ERE matching a single character or an ERE
enclosed in parentheses is followed by an interval expression of the
format {m}, {m,}, or {m,n},
it matches
(together
with that interval expression) what repeated
consecutive occurrences of the ERE would match.
The values of m and n are decimal integers in the range
0mn{RE_DUP_MAX}
where m specifies the exact
or minimum number of occurrences and n
specifies the maximum number of occurrences.
The expression {m} matches exactly m
occurrences of the preceding ERE,
{m,} matches at least m occurrences,
and {m,n} matches any number of occurrences
between m and n, inclusive.
For example, in the string ``abababccccccd'' the ERE c{3} is matched
by characters seven through nine, and the ERE (ab){2,} is matched
by characters one through six.
An occurrence of multiple adjacent duplication symbols (+, *, ?, and intervals)
produces undefined results.
Two EREs separated by the special character vertical line (|)
match a string that is matched by either.
For example, the ERE a((bc)|d) matches the string ``abc''
and the string
``ad''. Single characters, or expressions matching single characters,
separated by the vertical line and enclosed in parentheses,
are treated as an ERE
matching a single character.
The ERE order of precedence, from high to low, is shown in the following table.
Collation-related bracket symbols
[= =] [: :] [. .]
Escaped characters
\special character
Bracket expression
[]
Grouping
()
Single-character ERE duplication
* + ?{m,n}
Concatenation
Anchoring
^ $
Alternation
|
An ERE can be limited to matching strings that begin or end a line; this
is called anchoring. The circumflex and dollar-sign bracket special
characters are considered ERE anchors when used anywhere
outside a bracket expression.
This has the following effects:
A circumflex outside a bracket expression anchors the (sub)expression
it begins to the beginning of a string. Such a (sub)expression
can match only a sequence starting at the first character of a string.
For example, the EREs ^ab and (^ab)
match ab in the string ``abcdef''
but fail to match the string ``cdefab'', and the ERE
a^b is valid, but can never match because the ``a''
prevents the expression ^b
from matching, starting at the first character.
A dollar sign outside a bracket expression anchors the
(sub)expression it ends to the end of a string;
such a (sub)expression
can match only a sequence ending at the last character of a string.
For example, the EREs
ef$ and (ef$) match ``ef'' in the string ``abcdef'',
but fail to match in the string
cdefab, and the ERE e$f is valid,
but can never match because the ``f''
prevents the expression e$ from matching, ending at the last character.
Error codes
Exit status returns 0 if any matches are found,
1 if none are found, and 2 for syntax errors or inaccessible files
(even if matches were found).
Files
/usr/lib/locale/locale/LC_MESSAGES/uxcore.abi
language-specific message file
(see LANG on
environ(5)).
 .c would print the first
instance of a line beginning with ``main'' in all files that match
the expansion of ``
.c would print the first
instance of a line beginning with ``main'' in all files that match
the expansion of ``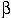 )
is placed in the collation sequence after ``r'' and ``s''
but before ``t'' (and that it maps to the sequence ``ss''
for collation purposes),
then the expression [r-s] matches only ``r'' and ``s'',
but the expression
[s-t] matches ``s'', ``
)
is placed in the collation sequence after ``r'' and ``s''
but before ``t'' (and that it maps to the sequence ``ss''
for collation purposes),
then the expression [r-s] matches only ``r'' and ``s'',
but the expression
[s-t] matches ``s'', ``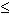 m
m